Apache Hive はHadoopの上に構築されたデータウェアハウス 構築環境であり、データの集約・問い合わせ・分析を行う。Apache Hiveは当初はFacebookによって開発されたが、その後Netflixのようにさまざまな団体が開発に参加し、またユーザーとなった。 Hive はAmazon Web ServicesのAmazon Elastic MapReduceにも含まれている。
特徴と機能
Apache HiveはHadoop互換のファイルシステム(たとえばAmazon S3)に格納された大規模データセットの分析を行う。使用には、map/reduceを完全にサポートしたSQLライクな「HiveQL」という言語を用いる。クエリの高速化のため、ビットマップインデックスを含めたインデクス機能も実装している。
標準設定では、Hiveはメタデータを組み込みApache Derbyデータベースに格納するが、オプションとしては別に用意したクライアント・サーバデータベース(たとえばMySQL)に格納させることもできる。
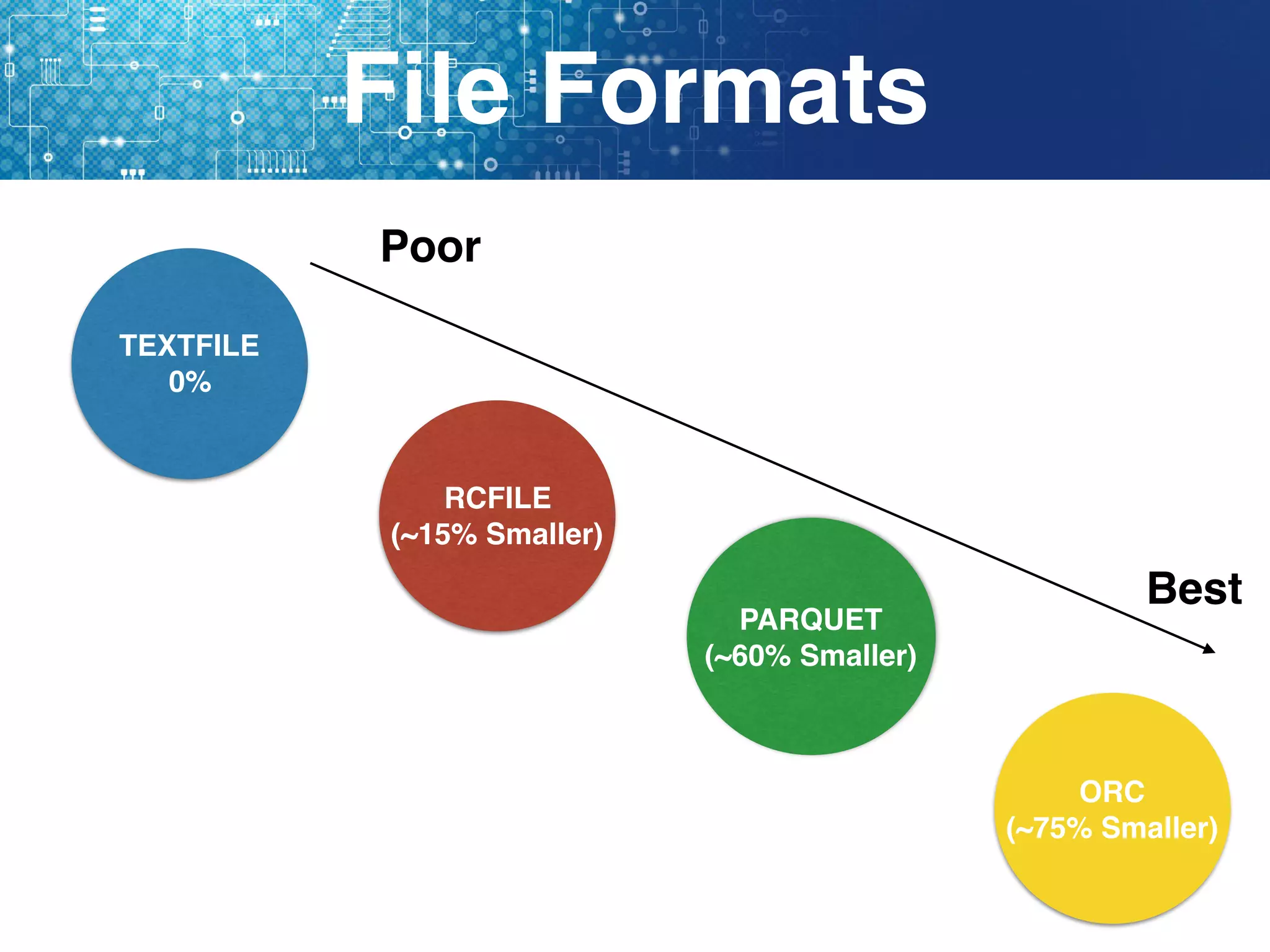
現在、Hiveがサポートするファイルフォーマットは3種類あり、それらはTEXTFILE, SEQUENCEFILE および RCFILEである。
Hiveが提供する機能には他には次のようなものがある:
- 高速化のためのインデックス作成
- 別の種類のストレージタイプ。たとえばプレーンテキスト・RCFile・HBaseなど
- クエリ実行時のセマンティックチェック時間を大幅に短縮するため、メタデータを関係データベース管理システム (RDBMS) に格納する機能
- Hadoop環境に格納された圧縮データを扱う機能
- 日付型・文字列型を扱ったり他のデータ操作を可能とする組み込みユーザ定義関数(UDF)。組み込み関数で用意されていない機能もユーザが自作UDFを作成することで対応することが可能
- SQLライクなクエリ言語(Hive QL)。これは内部的にMap/Reduceジョブに変換される
HiveQL
HiveQLはSQLに基づいているものの、厳密にはSQL-92をフルサポートしてはいない。たとえばSQLにない複数テーブルインサートやcreate table as selectは可能だが、インデクスに関しては限定的なサポートに留まっている。また、HiveQLはトランザクションやマテリアライズドビューの機能はもたず、副問い合わせのサポートも限定的である。。
内部的には、コンパイラがHiveQL文をMap/Reduceジョブの有向非巡回グラフに変換し、それがHadoopに渡され実行される。
関連項目
- Apache Pig
- Apache Sqoop
- Jaql
参照
外部リンク
- 公式ウェブサイト
- Hive A Warehousing Solution Over a MapReduce Framework - Original paper presented by Facebook at VLDB 2009
- Using Apache Hive With Amazon Elastic MapReduce (Part 1) and Part 2 - YouTube, presented by an AWS Engineer